Procédures à suivre pour apparier des données en Suisse
Apparier des données administratives : procédure de l’Office Fédéral de la Statistique
Pour apparier des jeux de données dont au moins un provient de l’administration fédérale, l’appariement de données est effectué par l’Office Fédéral de la Statistique. L’appariement de données pour le compte de tiers est soumis à une procédure clairement définie et garantissant un haut niveau de protection des données.
La procédure à suivre pour déposer une demande d’appariement à l’OFS est la suivante (la procédure détaillée est accessible sur le site de l’OF
- L’utilisateur des données complète un formulaire de demande d’appariement, disponible sur le site web de l’OFS. Le formulaire est accessible et téléchargeable en suivant ce lien.
2. Le formulaire complété doit être renvoyé à cette adresse .
3. L’OFS examine la demande et contacte éventuellement l’utilisateur pour des compléments d’information.
Pour que la demande puisse être validée, les conditions suivantes doivent être remplies :
Pour que l’OFS puisse effectuer un appariement pour le compte d’un tiers, les critères suivants doivent être remplis (source OFS) :
Critères de sécurité :
-L’appariement doit être réalisé « à des fins de statistique publique ou à des fins scientifiques, et non dans un but administratif ou autre ».
-L’appariement « doit se faire dans le respect des prescriptions légales ; il doit porter sur des données couvertes par la LSF [Loi sur la statistique fédérale]
-La sécurité et la protection des données doivent être garanties, notamment pour les données sensibles :
Seules des données anonymes sont transmises, c’est-à-dire des données qui ne permettent pas d’identifier un individu.
Les données ne doivent pas être désanonymisées ou appariées avec d’autres données.
Une fois l’analyse effectuée, les données sont détruites ou rendues à l’OFS. »
Critères méthodologiques et techniques :
-Les données à apparier et les données qui résultent de l’appariement sont de qualité suffisante, la méthode choisie est adaptée et les données utilisées se prêtent au thème étudié.
-Les sources des données à apparier contiennent des identificateurs (anonymisés) identiques. »
La demande d’appariement doit en outre satisfaire aux critères suivants :
-Elle doit s’inscrire dans un travail que vous effectuez pour un institut de recherche reconnu (par ex. université) ou pour un organe d’une administration fédérale, cantonale ou communale.
-Elle s’inscrit dans un projet qui vise un but statistique (et non administratif). Si le but est scientifique, la demande doit contenir un bref descriptif du but du projet, de sa pertinence et de son intérêt pour la science en général (but du projet ; description détaillée des données utilisées comme output ; indication de l’utilisation concrète et éventuelle maquette de la publication).
-La demande porte sur des données statistiques de l’administration fédérale. » (Source : OFS)
4. Une fois la demande effectuée :
L’OFS accepte la demande : un contrat, envoyé à l’utilisateur par l’OFS, doit être signé par les deux parties. Si les chercheurs/utilisateurs veulent apparier les jeux de données de l’administration avec leurs propres jeux de données, ils doivent envoyer ces derniers à l’OFS pour que l’OFS puisse effectuer l’appariement. L’appariement est ensuite effectué grâce à la création d’une clé d’appariement puis l’OFS transmet les données anonymisées à l’utilisateur.
L’OFS refuse la demande : l’OFS informe l’utilisateur des raisons de sa décision négative.
Apparier des données de recherche et des données privées
Si l’appariement de données administrative est bien règlementé et suit des procédures précises, ce n’est pas le cas de l’appariement des données de recherche et des données privées. Il n’existe pas de normes ni même de principes régissant la manière dont ces données doivent être utilisées pour la recherche.
Si les données sont mises à disposition sur une plateforme d’archivage de données, l’utilisateur peut alors les télécharger et les utiliser dans le respect des restrictions et conditions d’utilisations spécifiées. Sinon, l’utilisateur des données peut contacter le propriétaire des données pour accéder aux données.
Procéder à un appariement de données consiste à créer des paires d’enregistrements des individus ou d’entités similaires présents dans les différents fichiers à apparier. Pour identifier les individus ou entités qui se correspondent dans les différents fichiers, il existe une grande variété de méthodes.
Appariement de données déterministes
Au sein des jeux de données, les individus sont souvent décrits par un identificateur, ou à défaut, par une ou plusieurs variables d’identification, telles des informations sur l’état civil, les noms et prénoms, les lieux de résidences etc… L’appariement de données est dit déterministe si un identificateur unique commun ou une combinaison de variables permet une comparaison exacte entre les individus ou entités des différents jeux de données.
– Lorsque des identificateurs uniques sont communs aux différents jeux donnés à apparier, un appariement déterministe simple peut être effectué : les données sont appariées sur la base des identifiants uniques et communs aux différents jeux.
– En l’absence d’un identifiant unique, l’appariement déterministe peut être réalisé à partir d’identifiants indirects qui sont alors une combinaison de variable permettant d’identifier les individus ou entités similaires dans différents jeux de données. Ces variables doivent être complètes, précises et robustes.
Methodologie d’appariement de données
Apparier des données individuelles
Pour réaliser un appariement à partir d’une combinaison de variables, l’harmonisation des données est une étape préalable essentielle. Elle permet de garantir que les identifiants potentiels des différentes sources de données puissent correspondre les uns aux autres.
Quelques règles de base pour harmoniser les données :
- Nettoyer les données par la conversion des lettres en majuscules et l’élimination des accents
- Supprimer les mots inutiles ou redondants et les éléments indésirables des chaînes de caractères
- Convertir les mots en orthographe standardisé.
- Recoder des chaînes de caractères pour les normaliser autour de valeurs communes (par exemple, si des diminutifs sont parfois utilisés, et parfois non utilisés, pour nommer la même entité, les diminutifs peuvent être enregistrés par le nom entier, pour normaliser les données.
Pour aller plus loin sur l’harmonisation des données :
–QuickCharmStats développé par le GESIS pour « réduire le temps et les efforts que les chercheurs consacrent à l’harmonisation et au recodage des variables en vue de l’analyse statistique .
-Outils Biobanque du programme européen FP7 BioSHaRE (Biobank Standardisation and Harmonisation for Research Excellence in the European Union) développés dans le domaine des sciences médicales pour évaluer la compatibilité des données collectées et le lien entre les cohortes de différents pays européens.
Appariement de données probabilistes
En l’absence de variables unique ou de combinaison de variables pouvant permettre des appariements déterministes, une autre famille de méthodes consiste à évaluer la probabilité qu’une paire d’enregistrements de fichiers distincts puisse correspondre à un même individu ou entité. Les liens probabilistes attribuent des poids à chaque paire d’enregistrements indiquant la probabilité d’une correspondance réelle. Il y a une grande variété d’approches pour l’appariement de données probabiliste.
Il existe des outils qui peuvent aider à réaliser des appariements probabilistes :
La page Github présentes différents logiciels de record matching :
Atylmo https://github.com/pierrepita/atyimo
Dedupe https://github.com/dedupeio/dedupe
fastLink https://cran.r-project.org/web/packages/fastLink/index.html
FEBRL https://sourceforge.net/projects/febrl/
FRIL http://fril.sourceforge.net/
FuzzyMatcher https://pypi.python.org/pypi/fuzzymatcher
JedAI http://jedai.scify.org/
PRIL https://github.com/LSHTM-ALPHAnetwork/PIRL_RecordLinkageSoftware
RecordLinkage (R) https://github.com/J535D165/recordlinkage
RELAIS https://www.istat.it/en/methods-and-tools/methods-and-it-tools/process/processing-tools/relais
ReMaDDer http://remadder.findmysoft.com/
Splink https://github.com/moj-analytical-services/splink
The Link King http://www.the-link-king.com/
L’article “Karr, A. F., Taylor, M. T., West, S. L., Setoguchi, S., Kou, T. D., Gerhard, T., & Horton, D. B. (2019). Comparing record linkage software programs and algorithms using real-world data. PloS one, 14(9), e0221459.” propose également une comparaison des quatre logiciels d’appariement suivant :
-R (Version 3.4.0, RecordLinkage package)
https://cran.r-project.org/web/packages/RecordLinkage/index.html
-Merge ToolBox (MTB, Version 0.75)
https://www.uni-due.de/~hq0215/documents/mtb_gettingstarted.pdf
-Curtin University Probabilistic Linkage Engine (CUPLE, shortened in figures and tables to CU)
https://healthsciences.curtin.edu.au/health-sciences-research/research-institutes-centres/centre-for-data-linkage/
-Link Plus (LP, Version 2.0)
https://www.cdc.gov/cancer/npcr/tools/registryplus/lp.htm
Pour réaliser des appariements de données avec R, vous pouvez également consulter les tutoriels ici.
Statistitic Canada propose également l’outils G-Coup.
Apparier des données contextuelles
Les données contextuelles, qu’est-ce que c’est ?
Les données contextuelles se rapportent à l’environnement dans lequel évolue un individu ou une entité.
L’environnement est un niveau macro qui résulte de l’agrégation des pratiques et des comportements des individus au niveau micro, et des interactions entre les individus. L’environnement décrit par les données contextuelles peut-être un territoire à différentes échelles (quartier, ville, district, canton, pays, etc.) ou une structure institutionnelle (organisation comme une entreprise, une école etc.) avec des règles et des processus spécifiques qui régissent la manière d’agir des individus (Johnson et al. 2002). L’environnement peut-être également un réseau formé par les interactions entre des individus ou des entités (Pumain, 2003).
Les données contextuelles, à quoi ça sert ?
Au sein de cet environnement, des pratiques et des comportements implicites induisent une coévolution ou une interdépendance comportementale d’individus ou d’entités appartenant à un même environnement (Huckfeldt et Sprague, 1993 ; Johnson et al. 2002). Le niveau macro des territoires et des organisations peut ainsi parfois être plus pertinent que le niveau individuel pour comprendre des phénomènes socio- comportementaux ou des phases de l’histoire” (Sprague, 1982 ; Pumain, 2007) et pour les sciences médicales, permet de mieux comprendre les liens entre l’environnement et le développement des maladies. Les données contextuelles et l’analyse à plusieurs niveaux qui en résulte permettent d’objectiver la dépendance entre le comportement d’un individu et les processus contextuels, ainsi que d’intégrer l’impact de la localisation, de la délimitation des contextes ou des environnements ou des effets du temps sur les résultats de l’analyse (Grossetti, 2011).
Grossetti, M. (2011). L’espace à trois dimensions des phénomènes sociaux. Échelles d’action et d’analyse. SociologieS.
Huckfeldt, R., Plutzer, E., & Sprague, J. (1993). Alternative contexts of political behavior: Churches, neighborhoods, and individuals. The Journal of Politics, 55(2), 365-381.
Johnson, M., Shively, W. P., & Stein, R. M. (2002). Contextual data and the study of elections and voting behavior: connecting individuals to environments. Electoral Studies, 21(2), 219-233.
Pumain, D. (2003). Du local au global, une géographie sans échelles ? Cybergeo: European Journal of Geography. Éditoriaux, mis en ligne le 12 septembre 2003.
L’appariement avec des données contextuelles consiste alors à relier les informations sur un individu (niveau micro) avec les informations sur son environnement (niveau macro), on ne va donc pas lier des informations relatives à un même individu ou entité, mais on va lier des informations concernant un individu au niveau micro avec des informations agrégées au niveau macro de l’environnement au sein duquel il évolue.
Apparier des données contextuelles sous formes de classes/typologie
Les typologies socio-professionnelles et les nomenclatures d’activités socio-économiques sont des ensembles d’emplois ou d’activités économiques regroupées en catégories, dont la construction est basée sur le degré de proximité entre les emplois ou activités économiques qu’elles décrivent. Ces catégories sont souvent subdivisées en sous-catégories, qui décrivent des ensembles d’emplois ou d’activités plus proches entre eux que des autres d’emplois ou d’activités de leur catégorie. Ces catégories sont décrites par des codes à plusieurs chiffres. La longueur du code (nombre de chiffres) varie selon le niveau de la catégorie. Les grandes catégories sont décrites par un nombre, généralement à 1 chiffre, et les n sous-catégories sont décrites par un code à n chiffres.
L’appariement avec les données contextuelles peut être un simple couplage déterministe basé sur le code des catégories d’activités socioprofessionnelles et économiques. Si un tel code n’est pas inclus dans les ensembles de données, ils peuvent être reliés sur la base d’une série d’indicateurs relatifs, par exemple, aux noms et à la localisation des activités professionnelles et des entreprises. Comme pour les données individuelles, étant donné la variabilité de l’écriture des noms d’entreprises, d’activités, de professions, les données doivent être harmonisées (renvoi vers le paragraphe correspondant) avant d’être appariées.
Apparier des données spatialisées – à l’aide d’un SIG
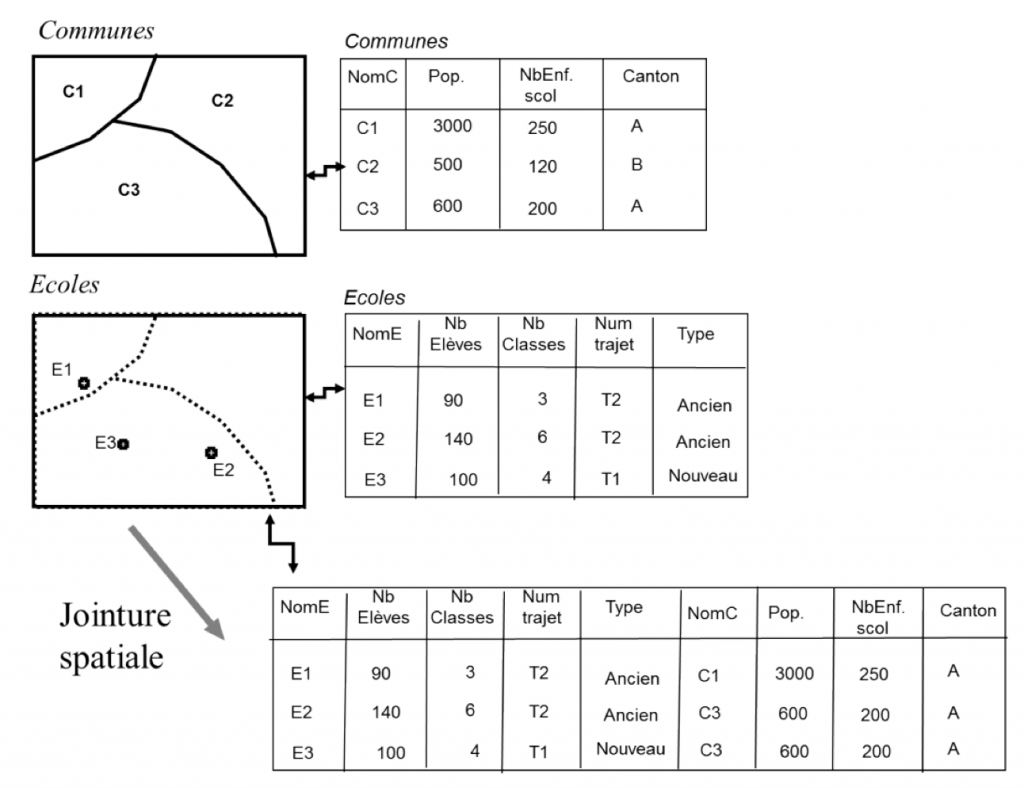
Pour les données territoriales, le processus peut être similaire si les données peuvent être associées à un code territorial (par exemple, le code de la commune ou du canton), ou à des variables d’identification telles que le nom des communes et leur subdivision en unités territoriales supérieures. La spécificité des données territoriales est que le couplage peut également être effectué à l’aide d’un système d’information géographique (SIG). Cela permet, en l’absence d’un code commun pour les ensembles de données, d’éviter les erreurs dans un couplage basé sur un ensemble de variables nominatives. La liaison avec un SIG est réalisée en géolocalisant les emplacements des individus et les informations contextuelles spatialisées, en les projetant dans un SIG et en effectuant une jointure spatiale.
1/ Géolocalisation de l’information :
Géolocaliser l’information, qu’il s’agisse d’adresses ou de noms de communes, de districts etc. Le géocodage consiste à attribuer une latitude et une longitude pour projeter une localité sur une carte ou dans un SIG. Dans le cas d’une adresse, il s’agit d’une géolocalisation précise. Dans le cas d’un nom de commune ou de district, une latitude et une longitude correspondent au centroïde de l’unité territoriale.
Pour géolocaliser les données, il existe des logiciels gratuits qui peuvent être utilisés directement en ligne pour géolocaliser les données tels :
Batchgeo
French public data open platform
Il peut également être réalisé avec un logiciel SIG :
– QGIS, avec les plugins Geocode et MMQGIS (Des tutoriels pour le géocodage d’adresses avec QGIS sont disponibles (en français) sur le site du Blog idgeo
et sur le site du Blog “SIG et Territoire“.
–ArcGIS desktop avec la boîte de dialogue de géocodage des adresses ArcMap :
–ArcGIS (pro) avec l’outil Géocode Adresses dans la fenêtre Géoprocessing
2/ Approche générale pour réaliser une jointure spatiale :
-Téléchargez les fichiers des couches de délimitation territoriale (pays, cantons, districts, communes …) dans un format Shapefile lisible par le SIG. Une fois ces deux étapes réalisées, un lien spatial sous SIG permettra de relier les données géocodées aux fichiers des couches de délimitation territoriale sous SIG.
-Pour effectuer la jonction spatiale, ouvrez le fichier de couche dans un logiciel SIG et attribuez-lui la projection dédiée.
-Importez le fichier d’adresses géocodées dans un format lisible par le logiciel SIG utilisé (souvent les formats csv. et txt.), convertissez-le en un fichier de forme (point) et projetez-le dans le SIG où se trouve le fichier de forme des entités territoriales avec la même projection que ce dernier. Faites la jonction spatiale entre les deux fichiers.
3/ Tutoriels pour réaliser une jointure Spatiale sous QGIS, ArcGIS Desktop et ArcGIS Pro:
– QGIS
– ArcGIS desktop
– ArcGIS Pro
Trouver des données contextuelles sur la Suisse
- Typologies territoriales
| Name | Information provided | Digits and classes | Link | Institution |
| NUTS NOMENCLATURE OF TERRITORIAL UNITS FOR STATISTICS | NUTS 1: major socio-economic regions NUTS 2: basic regions for the application of regional policies NUTS 3: small regions for specific diagnoses | NUTS 1: 3 digits (2 letters, 1 no.) NUTS 2: 4 digits (2 letters, 2 no) NUTS 3: 5 digits (2 letters, 2 no, 1 lett.) | https://ec.europa.eu/ eurostat/web/nuts/ background | Eurostat |
| Agglomerations and Centres outside the agglomeration (2012) | Agglomerations and number of communes contained in agglomerations. | Code agglomération : 3 to 4 digits Codes centres hors agglomération : 5 digits | https://www.bfs.admin.ch/bfs/fr/home/statistiques/themes-transversaux/analyses-spatiales/niveaux-geographiques/typologies-territoriales.assetdetail.188853.html | SFSO |
| Institutional levels : Municipalities/Communes | For municipalities in agglomerations: agglomeration code For oriented communes: code of the first and second agglomeration centre. | SFSO code of Commune: 2 to 4 digits | https://www.bfs.admin.ch/bfs/fr/home/statistiques/themes-transversaux/analyses-spatiales/niveaux-geographiques/typologies-territoriales.assetdetail.188853.html | SFSO |
- Typologies socio-professionnelles
| Name | Information provided | Digits and classes | Link | Institution |
| Socio-professional categories 2010 | 17 categories | Codes of 1 to 3 digits depending on the level of detail | https://www.bfs.admin.ch/bfs/fr/home/statistiques/travail-remuneration/nomenclatures/spk2010.assetdetail.3962878.html | SFSO |
| International Standard Classification of Occupations – ISCO 88 (COM) | 9 categories | Codes of 1 to 4 digits depending on the level of detail | https://www.bfs.admin.ch/bfs/fr/home/statistiques/travail-remuneration/nomenclatures/isco88com.html | SFSO |
| Swiss Nomenclature of Occupations 2000 | 9 categories | Codes of 1 to 5 digits depending on the level of detail | https://www.bfs.admin.ch/bfs/fr/home/statistiques/travail-remuneration/nomenclatures/sbn2000.html | SFSO |
| Swiss Nomenclature of Occupations CH-ISCO-19 | 9 categories | Codes of 1 to 5 digits depending on the level of detail | https://www.bfs.admin.ch/bfs/fr/home/statistiques/travail-remuneration/nomenclatures/ch-isco-19.html | SFSO |
- Typologies des activités économiques
| Name | Information provided | Digits | Link | Institution |
| General Classification of Economic Activities / Nomenclature générale des activités économique (NOGA) | Socio-professional categories 2010 Integrated into the Register of Companies and Establishments | 1 to 5 digits 794 economic activities | https://www.bfs.admin.ch/bfs/fr/home/statistiques/travail-remuneration/nomenclatures/spk2010.assetdetail.3962878.html | SFSO |
| International Standard Classification of Occupations (ISCO-08) | International Standard Classification of Occupations The ISCO-08 structure is the result of the aggregation of the ISCO 88 unit groups. | 436 unit group 130 minor groups 43 major group | https://www.bfs.admin.ch/bfs/fr/home/statistiques/travail-remuneration/nomenclatures/isco88com.html | SFSO |
| Name | Information provided | Link | Institution |
| Catalogues et banques de données | Population, economy, land use, environment Country, Communes, cantons, districts Données sous forme de tableaux interactifs. Données sélectionnables par thèmes, enquêtes, niveau géographiques et mots-clés | https://www.bfs.admin.ch/bfs/fr/home/statistiques/catalogues-banques-donnees/donnees.html | SFSO |
| Geodonnées GEOSTAT | Limites communales, statistique de la population agrégée à l’hectare, statistique structurelle des entreprises, statistique de superficies, données relatives aux sols | https://www.bfs.admin.ch/bfs/fr/home/services/geostat/geodonnees-statistique-federale.html | SFSO |
| Données de bases des unités administratives | “Référentiels de coordonnées: série de coordonnées (x, y, z) point géodésique horizontal et vertical AGNES, Géoïde en CH1903, Géoïde en ETRS89” “Unités administratives Convention Alpine, Frontière Nationale, Inventaire des logements” Adresses: répertoire officiel des localités avec le code postal et le périmètre associés Parcelles cadastrales | https://www.geo.admin.ch/fr/geoinformation-suisse/repertoire-inspire/donnees-de-base.html | SFSO |
| geocat.ch Catalogue suisse de géométadonnées | Catalogue des métadonnées des géodonnées Suisses | https://www.swisstopo.admin.ch/fr/cartes-donnees-en-ligne/catalogue-metadonnees-geocat.html | swisstopo |
| Répertoire [INSPIRE] | Toutes les géodonnées numériques disponibles de manière centralisée, subdivisé par thèmes. | https://www.geo.admin.ch/fr/geoinformation-suisse/repertoire-inspire.html | swisstopo |
- Données socio-économiques et géographiques à l’échelle des Cantons